Midjourney launched a new “personalization” feature this week, and I think it presents an interesting and valuable contrast to the kind of direct manipulation interfaces for interacting with AI systems that I’ve been advocating for. I also think this implementation of personalization reveals an unconventional way of thinking about style in creative tools, not by concrete stylistic traits but by a style’s relationship to a universe of other tastes or style preferences.
This is my stream-of-consciousness notes on both ideas.
Instrumental and intrinsic interfaces
With personalization, Midjourney users can steer generated images toward a specific style of their preference by choosing a few hundred images that exemplify that style. This method allows users to articulate and build on their style preferences much more accurately, and perhaps easily, than would be possible with a conventional text prompt. I hypothesize that, under the hood, Midjourney trains a steering vector or LoRA adapter that can steer their models’ outputs toward users’ preferred styles. From the demos I’ve seen online, it seems to work quite well.
I’ve been long advocating for interfaces where users observe the concepts and styles a model has learned during training and directly manipulate some interface affordance to steer the model toward their desired output. This leans on the user to discover their preferences by exploring the model’s output space over the course of using the model. But more importantly, it lets each user build a strong internal mental model of how their tool maps inputs to outputs. It exposes a kind of laws of physics about the generative model’s understanding and expression of concepts and styles.
By contrast, Midjourney’s personalization system automates much of the style discovery process on behalf of the user. In place of a user building up a mental model of the ML model’s output space, the personalization system takes binary preference signals from the user and automatically tries to infer the user’s intent within the model’s space of concepts and styles.
I compare the ideological difference in design to the difference between a navigation system that shows you but a list of turn-by-turn directions, and one that shows you some routes highlighted on a map:
- In the turn-by-turn system (Midjourney’s personalization), the system takes a user command and automatically interprets it to get the user the result they need. It’s an instrumental interface, as in the interface is an instrument to achieve a goal, and the goal is what’s important.
- In the map-with-route system (direct manipulation), the user must do some of the work of understanding what they see (the map), and developing a mental model of how to apply it to their context (reading the map). In exchange for this deeper involvement, the user learns a useful mental model (their local geography) that can help them in future uses of the tool, or elsewhere in their life. This is an intrinsic interface – the value of the interface isn’t just in the result, but also intrinsic to its use.
One simple litmus test to distinguish these two types of interfaces is to ask, “Would the user care if I replaced the interface with a button that magically solved their problem?” If the user won’t care, an instrumental interface is the right fit. But if the user does care, they ultimately care about the value of engaging with the interface itself, and an intrinsic interface may be better. It may be possible to replace a turn-by-turn navigation system with a magic button, but not a map.
There’s a big space in the world for instrumental interfaces. Lots of people want to get a good output or result, and don’t really care how they get it. But I’m much more interested in the intrinsic interfaces, the ones that require a bit more effort, but can teach us to internalize knowledge about the domain the interface represents.
The idea of instrumental and intrinsic interfaces has been brewing in my mind for a long time, and I thank Parthiv in particular for planting the initial seeds and helping grow them into the version I wrote about here.
Measuring with taste
Another way to think about Midjourney’s personalization feature is to conceptualize each “personalization code” (however it’s represented under the hood) as a pointer into the model’s internal representation space of visual styles, the model’s “style space”.
Anytime we have a space and enough reference points in the space, we can build a coordinate system out of it. Rather than describing a point in the space by their absolute positions, we can describe a location in the space by enumerating how far that point is from all the other reference points whose locations we already know.
In other words, if we think of Midjourney’s personalization codes as pointers into specific parts of the model’s style space, we can imagine building a kind of “style coordinate system” where we describe a particular image’s style as “0.5 of personalization style A, 0.2 of personalization style B” and so on.
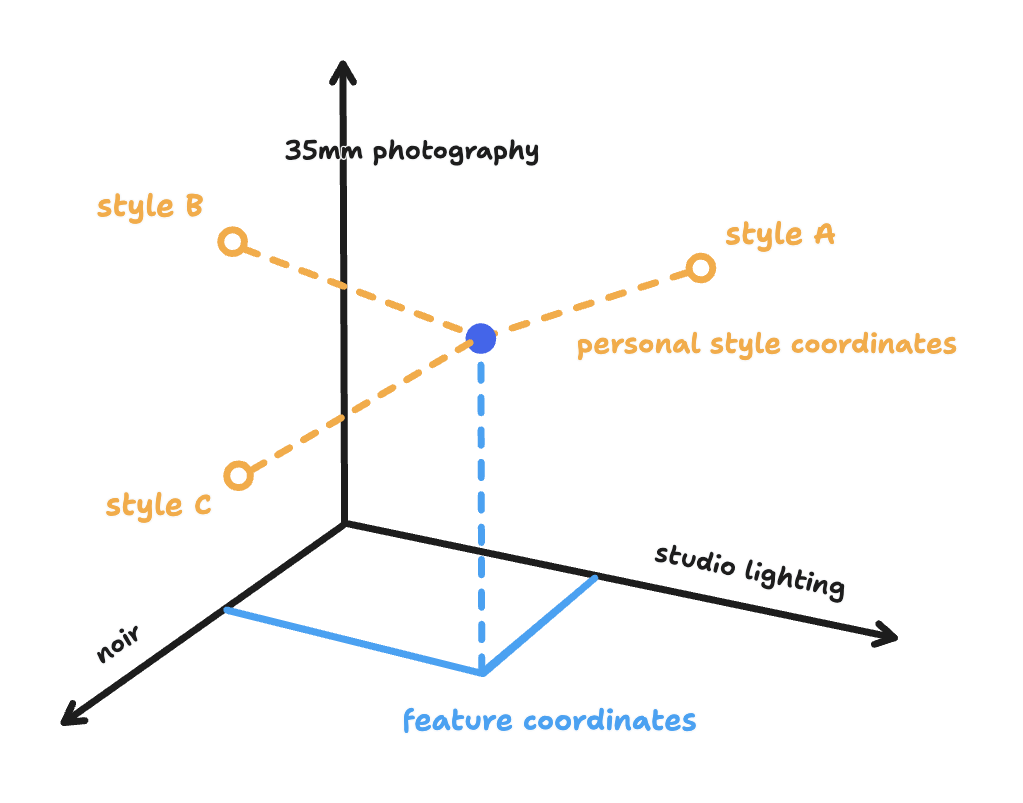
Of course, we can choose a different set of reference points in our style space. For example we can choose concrete, interpretable elements of style we have names for, like “studio lighting”, “35mm film photography”, or “noir”. In this style coordinate system, we could describe a particular image as “0.7 studio lighting, 0.4 noir” and so on.
One of the technical foundations for my recent research, mapping interpretable features in foundation models, is doing something quite similar to the latter option, finding “features” in the model’s space of concepts that we can use to very precisely steer models towards specific voice, style, or topics. Over time, we’ll learn to discover more detailed feature maps for more capable models, giving us a very detailed and human-readable coordinate system for ideas and styles.
Midjourney’s implementation of personalization is not technically unique. There is no shortage of methods researchers have invented to add a style “adapter” to some generative model from a few examples: LoRA, steering vectors, textual inversion, soft prompts, and so on.
What makes style adapters like Midjourney’s interesting is that it leads me to imagine a very different kind of feature map for generative models, one where each coordinate axis isn’t a specific concept or element of style that humans can quickly label, but a vibe derived from someone’s unique preference fingerprint.
Slicing up the latent space not by concepts, but by vibe. Measuring reality by the unit of tastes.
← Some applied research problems in machine learning
Prism: mapping interpretable concepts and features in a latent space of language →
I share new posts on my newsletter. If you liked this one, you should consider joining the list.
Have a comment or response? You can email me.