The Lua programming language is unusual among its peers. It’s a dynamically typed, scripting language with a really small core (100-200kB), but runs efficiently, has far simpler semantics than other similar languages, and is just as old as the giants like JavaScript, Python, and Ruby – first made in a research lab 1993.
Lua is also special in that it’s implemented as a very portable, pretty readable, small C program. I’ve wanted to dive into its internals for a long time, and spent some time today reading the design paper behind Lua 5.0’s internals.
Here’s an incomplete collection of what I found most interesting and insightful in that paper. If you’re interested in this sort of thing, I recommend you check it out! It reads easily compared to more academic papers and has lots of little details showing off thoughtful design in the face of interesting constraints of simplicity and size.
This post is longer than usual. You can jump between the technical sections from this table of contents.
- Size and simplicity as design constraints
- A more dynamic self-resizing table
- Lua VM is a register machine
- The destination register
- Branch instructions
- Double stacks and the coroutine stack
- Closures that are nice on heap allocation
- Garbage collection
- Minimal static analysis
- Orthogonal design
Size and simplicity as design constraints
The first thing that the paper lays out is the design constraints of the interpreter. Lua exists at a strange intersection of efficiency and minimalism: it must support a highly dynamic language, while also being suitable for running in embedded environments from video games to small IoT devices.
Usually, these goals are at odds. If you want your interpreter to be fast, you want to spend lots of processor time and memory to optimize the program before and during execution to make it efficient. But if you want the interpreter to fit in a small space and run on slow devices, there’s not a lot of time nor space to waste on optimizations.
This interplay between size and efficiency goals is what makes the design of Lua so interesting. Size constraints guide the language to be small, while efficiency constraints guide it to have few redundancies. The only way to achieve both is for the interpreter to be simple and elegant, and that’s what we get. I think this is what leads Lua to be a great example of orthogonal design, on which I’ll elaborate at the end of this post.
A more dynamic self-resizing table
Lua doesn’t have a distinction between a list-like data structure (like Python’s lists and Ruby’s Arrays), and a map-like data structure (like Python’s dicts and JavaScript’s objects). Instead, the only data structure per se in Lua is the table, which is a map / dictionary. The Lua authors call this the associative array. They all mean the same thing in practice – you can store values in a Lua table keyed by some value, and later retrieve it by that key.
Lua programs use tables as both dictionaries and lists. When used as lists, values are keyed and referenced by integer keys, used as indexes. This greatly simplifies the runtime, because the language and compiler need to support just one kind of a composite data structure, instead of supporting operations on both list-like data structures and tables. (Incidentally, Ink also takes after Lua, and offers just one data structure, also an associative array.)
The most straightforward way to implement Lua tables would be to use a hashmap. This is what previous versions of Lua does, but there’s room for efficiency. Because Lua programs so often use tables to emulate arrays, the interpreter can see big performance gains if it can access array-style (integer-keyed) table elements in constant time, like a real array. This would be a big improvement over paying the cost of hashing and linked-list traversal with every access into a table.
In Lua 5.0, the table is a hybrid data structure backed by both a hash table and an adjustable-size array. Array-style table entries are stored in the array portion, and all other keys, like string labels, are stored as entries in the hashmap. The paper outlines a simple algorithm to dynamically adjust the size of the array portion of the hashmap, to keep array accesses reasonably fast while avoid over-allocating memory for the array:
The computed size of the array part is the largest n such that at least half the slots between 1 and n are in use (to avoid wasting space with sparse arrays) and there is at least one used slot between n/2 + 1 and n (to avoid a size n when n/2 would do).
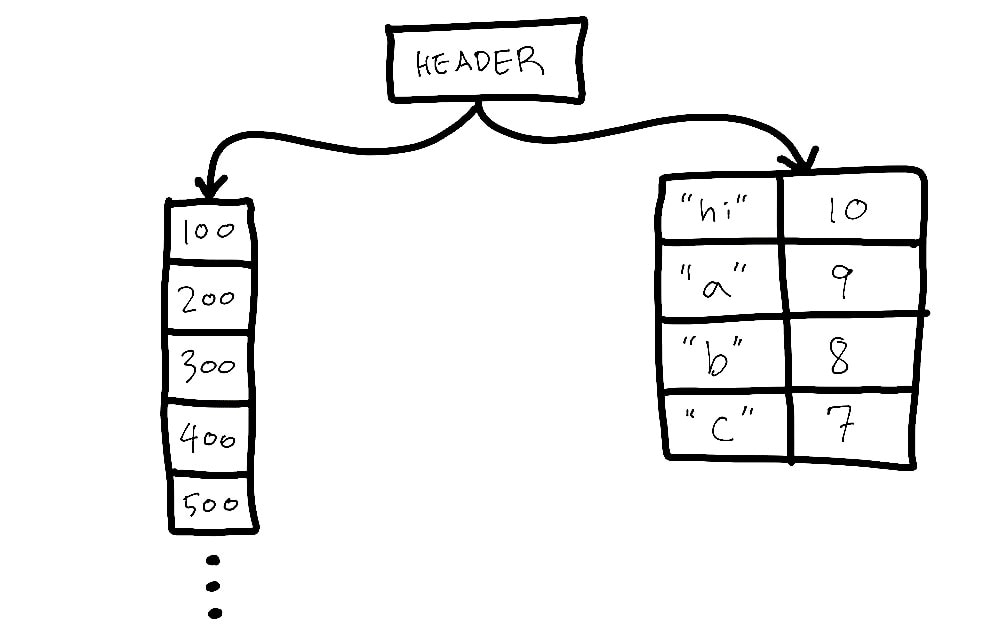
The resizing algorithm itself is simple – it fits in a single sentence. But it achieves enough performance gains in array-like table access patterns that the additional bit of complexity is worth the tradeoff.
V8, Chrome’s JavaScript engine, also uses a similar hybrid-dictionary optimization for some JavaScript objects. But compared to the relatively simple Lua design, V8’s JSObject data structure is much more complex to allow for even tighter optimizations at runtime.
Lua VM is a register machine
Lua’s interpreter is a bytecode virtual machine. The interpreter first walks the program text to transform it into a sequence of bytecode instructions for a virtual processor, and then a simple while-switch dispatch loop is used for running the program, one instruction at a time.
Here’s a healthy sampling of some of Lua’s 35 instructions:
MOVE A B- copy value from register B to AGETTABLE A B C- take the value from table B at key C and copy into register AADD A B C- add B and C together and place result into register AJMP sBx- move the program counter bysBxbytesEQ A B C- if A is the booleantrue, this tests thatB == C. Iffalse, this testsB != C. This instruction is followed by aJMP, as explained in the Branch instructions and JMP section.
Until 5.0, Lua’s VM was a stack machine. It used to operate against a single sequential, growable stack of values, pushing and popping values from the top of the stack. The 5.0 VM is a register machine, which operates on a set of virtual registers that can store and act on the local variables of a function, in addition to the traditional runtime stack.
The paper enumerates a few different benefits of the register-based design. While slightly more complex to implement, a register machine design aligns the instruction set better with both the Lua language itself, and with the underlying processor hardware that’s probably executing the VM code. Here, I’ll specifically examine one way this is true, and leave another for the section below on the destination register.
The register machine-based design of the VM aligns well with modern processors, which work on registers and fetch memory by the machine word (usually 32- or 64-bit in size). With this design, the virtual machine’s registers can map nicely to the processor’s physical registers. With most small functions, the processor could benefit from the one-to-one correspondence between the VM’s virtual registers and the CPU’s underlying registers to make functions more efficient. This is better than the previous stack machine design, where the VM operates on a single value at a time at the top of the stack, and values would often be pushed and popped from the stack, leading to more redundant copying and moving of values in memory.
(Correction, Sept 2020: As pointed out by a Reddit thread, the one-to-one correspondence between Lua registers and a processor’s physical registers is generally not true, because Lua values include a type tag, which can make the value itself larger than a machine word. The other benefits of a register machine design outlined here still stand.)
A consequence of the register machine design is that we can no longer assume virtual machine instructions always operate on values at the top of the stack. So instructions now need to contain more operands inside. Lua’s instructions are standardized on a 4-byte size. There’s a 6-bit opcode followed by operands ranging from 8 to 18 bits in size. On face, we might prematurely worry that this would bloat the size of the generated bytecode for a Lua program because each instruction is larger now with more operands. But the Lua authors claim that the overall increase in code size is negligible since register bytecode is more concise than stack bytecode, and any given program will now compile to a fewer number of instructions.
A more significant benefit of the larger, more compact instruction design is that the instruction itself contains all its operands. On most common architectures, this means the entire instruction fits in a single machine word and a single memory read. Thus on each instruction dispatch, the VM needs a single, predictable, branch-predictor-friendly memory fetch, probably from the cache, to read the instruction and its operands. This compares favorably to a stack machine, where instructions are stored separately from its operands, requiring the CPU to access multiple places in memory before a single instruction dispatch.
In these ways, the register machine maps to the underlying processor hardware more faithfully, and is more efficient as a result of this design.
The destination register
My favorite design detail of the Lua VM instruction set is that every one of Lua’s 35 virtual instructions all share the same first operand, which I’ll call the “destination register”. The destination register is where the value computed by the virtual machine for the instruction goes at the end of the instruction’s dispatch, if appropriate. (Some instructions, like jump or compare instructions, don’t really have a “result” to speak of, so they use this register for something else.)
Take the add instruction, for example. The ADD virtual instruction takes three operands: the destination register, and the two numbers to be added together.
lua: asm:
=== ===
sum = a + b ADD C A B
a = a + 1 ADD A A 1
Each of the lines of Lua code of a simple addition and assignment map to a single virtual instruction dispatch in the virtual machine. Variable assignment, which is usually common with addition and increment operations in Lua code, can be optimized into a single instruction alongside addition itself because of this additional operand in the instruction.
The add instruction in most other instruction sets take two operands, and usually deposits the resulting sum value in the first operand register or top of the stack. i.e. sum = a + b could be broken into two more conventional instructions (ignoring context-sensitive optimizations):
MOVE C A ; copy A into C temporarily
ADD C B ; add B into C, so C now holds the sum
Lua’s design here to have a separate destination register lends to some performance wins as a result of these optimization possibilities. Another example is the GETTABLE instruction, which takes three operands: the destination register, the table, and the key.
lua: asm:
=== ===
v = t["k"] GETTABLE V T K
Once again, we’re able to assign and access into the table in a single instruction decode and dispatch cycle because of the instruction design. This is a case of Lua’s instruction set more faithfully matching the semantics and common usages of the language, and this lends itself to a more elegant and efficient design.
Branch instructions
Most of Lua’s register machine instruction set is pretty standard, but I found the design of branching instructions noteworthy. To see why, let’s study how other instruction sets handle conditional branching in code.
Java Virtual Machine
The Java Virtual Machine (JVM) is a close analogue to the Lua VM – both are bytecode VMs. A difference we can ignore here is that the JVM is a stack machine, so the JVM instruction set operates implicitly on the values at the top of its stack, not registers.
Java bytecode for a conditional branching code for “if A and B are equal” might look like this:
program stack: A B
---
if_acmpeq <offset>
The if_acmpeq instruction is a mnemonic for: “if the top two values of the stack are equal (eq) by reference (a), jump ahead in the machine code by offset.” It’s a very specialized instruction. There’s a complement for not-equals (if_acmpne), and analogues for integer comparisons (if_icmpeq, if_icmpne, and so on). There are also equivalents for greater-than, greater-than-or-equals, less-than, and less-than-or-equals. Because these are single instructions, the bytecode representation is more compact, but the complexity of the instruction set and VM suffers as a result. This is a good tradeoff for the JVM, but Lua aims for something simpler and less redundant.
x86
Branch instructions in the JVM instruction set combined the “test” and “jump” parts of conditional execution into a single form. On x86 assembly, an instruction set closer to the metal of real processors, conditional branching code involves two instructions:
cmp ecx, edx
je equal
...
equal:
...
Here, the cmp instruction compares the values in the two registers ecx and edx, and the following je (jump-if-equal) instruction checks the comparison result (in a dedicated register), and jumps by an offset in the generated machine code. Let’s note here that there’s a direct relationship between the cmp and je instructions, and how they work together to achieve conditional branching in x86.
Lua
Lua’s branching instructions are two sequential instructions together, resembling the x86 equivalent – a conditional compare instruction, followed by a JMP that jumps the program to the correct next place. A conditional jump in Lua bytecode looks like this (with some editorialized notation on my part):
EQ <true> A B
JMP <offset>
...
(offset):
...
This code compares values at A and B, and if they’re equal, skips over the JMP instruction by incrementing the program counter during the EQ instruction; if they aren’t equal, the VM will continue to the JMP instruction, proceeding from the offset. In other words, the EQ instruction is defined such that if the equality test fails, it increments the program counter to skip the next JMP instruction. (In practice, both instructions are executed in one dispatch cycle, as an optimization, because a test instruction like EQ always precedes a JMP.)
There’s two interesting things about this design for conditional branching.
- There isn’t a need for a separate, special “jump-if-equal” instruction, as in x86. The conditional branching code re-uses the normal
JMP(jump) instruction to its benefit. - Because the comparison instruction doesn’t itself need to do double-duty as a jump instruction as in the JVM, it can have an extra operand to negate comparisons. i.e. Lua’s bytecode doesn’t need a “not-equal” instruction (whereas JVM has both a
if_acmpeqandif_acmpne) because the first operand can change to accommodate both use cases of “if equal” and “if not equal”.
In this way, the special trick of jumping the program counter in a comparison instruction like EQ results in a simpler and smaller instruction set. I find this design really elegant and minimally redundant.
Double stacks and the coroutine stack
Lua 5.0 introduces a level of concurrency to Lua programs with coroutines, which in my mind work a lot like continuations. The program can create a coroutine with a function that yields at various points, and a parent function can call into the coroutine’s execution at various points to run some child program with a level of concurrent reentrancy. To make this possible, each Lua coroutine has a separate stack, and when the currently running coroutine yields or returns, the program counter points to a different coroutine’s stack.
This means Lua can’t lean on the C stack to be the interpreter’s execution stack – there’s only one native C stack, and potentially many Lua coroutine stacks. Instead, it emulates each coroutine stack with an explicit program counter and custom stack of its own that’s independent from the C stack, pointing into the heap. It then uses frames on the C stack to keep track of the currently executing coroutine. Since coroutines can call into each other in a nested way, Lua needs to keep track of the hierarchy of currently running coroutines, and the C stack stores that information. The C stack is the “coroutine stack”.
One interesting implementation detail is that Lua’s per-coroutine “stack” is actually two separate stacks. One stack stores a sequence of invoked functions – the function, return address, program counter, and so on – and the other stack is a linear array of local variables (Lua values) accessed by the functions in the first stack. The frames of the call stack point into sections of the value stack to reference local variables and constants.
I haven’t quite wrapped my mind around the significance of this dual-stack design yet, but I suspect Lua benefits from some level of data locality and reduced data redundancy by storing the Lua values in a separate, contiguous chunk of memory than the call stack information.
Closures that are nice on heap allocation
Lua has closures, which is usually tricky to implement into a compiled language efficiently. Lua 5.0 introduces what I think is a novel way to implement closures in an interpreter that interoperates well with Lua’s stack design above.
The Lua authors call this invention upvalues. I don’t think I can do the topic justice myself, so if you’re curious about the precise implementation details of closures in Lua’s compiler, I’ll refer you to the paper above and the Lua source code.
In brief, the challenge with compiling closures into bytecode or machine code is a tradeoff: the most efficient way to store local variables is in the program stack. However, if a closure is returned and called later and it closes over (references) a local variable whose stack was already unwound in a previous return of a function, the closure breaks. So when the closure is returned and local variables are lost, any local variables that the closure references must be stored on the dynamically-allocated heap and garbage collected later. Lua’s upvalues system sacrifices a single pointer indirection per local variable to transparently move variables stored on the stack to the heap, whenever the variable goes out of scope. This keeps most functions efficient, while ensuring closures have correct behavior. It also achieves this without any complex control flow analysis that would render the Lua compiler much slower and more complex.
Garbage collection
The paper above omits most details about one critical part of the interpreter, the garbage collector. This is probably because it doesn’t have quite the number of interesting design decisions as the rest of the interpreter. It’s a more standard incremental mark-and-sweep GC.
Nonetheless, Lua has a garbage collector, and as of the 5.0 release, the GC is an incremental mark-and-sweep collector. The incrementality of the GC is particularly important for Lua because one of Lua’s more common use cases is in game development, where low latency is important. A 10ms stop-the-world GC pause in the middle of a frame would be critically bad. An incremental GC trades off slightly higher GC overhead on the interpreter for reentrancy, and it makes sense for Lua.
Lua also tries to reduce the GC pressure in how it allocates common Lua values. Numbers (represented as a C double most often, but customizable in the build) are stored directly, by value, in the Lua object representing the value. This means that numbers, alongside a few other simple values like booleans and nil, are not subject to GC – they’re allocated and deallocated directly on the Lua value stack, and simply copied around.
Lua strings are really byte buffers under the hood, and heap-allocated in Lua, but interned, so common strings, like object properties, share memory with each other.
Other Lua values are passed by reference, and subject to Lua’s GC.
Minimal static analysis
One interesting thing about the Lua interpreter is that it achieves the requisite efficiency and optimizations while still being a moderately fast, single-pass compiler, with very little static analysis of programs, like an SSA intermediate representation or control flow analysis.
Instead, most of the efficiency comes from machine-friendly, efficient representations of data and program state, and from having a small set of primitives (coroutines, tables, a small instruction set) from which more complex abstractions can be built easily.
Orthogonal design
I like Lua’s interpreter architecture. It brings some novel ideas to the table to combat the tyranny of the constraints of simplicity and size. But while each of these ideas are interesting and effective in isolation, I think these ideas also work harmoniously together to make something that’s more coherent and evident of good craftsmanship.
I’ll use the phrase orthogonal design to describe why I like the way these parts come together.
Two components of a system are orthogonal to each other when they affect the system in separate, independent ways. The X and Y axes of a 2-D plane are orthogonal – they represent completely separate, independent axes of movement, and a thing can move in those axes independently in either direction. Adding a Z axis that’s orthogonal to both X and Y will add yet another dimension of freedom. Orthogonal components in a system are desirable when they can be fit together because they most efficiently combine the strengths of each other, and leave little unnecessary redundancy.
Orthogonal design, then, is a design in which the individual design decisions are orthogonal to each other, and don’t overlap or step on each other’s toes while meshing well together. One example is Lua’s dual-stack design, its coroutine implementation, and its closure implementation with upvalues. These features enable very different, independent capabilities for the interpreter – a closure is conceptually unrelated to coroutines – but their individual implementations all interact elegantly with Lua’s stack design and don’t step on each other’s toes in the process. They build on each other without at any point canceling each other’s benefits out.
I think that’s what appeals to me about Lua’s software design: Small, specialized, well conceived parts working together harmoniously against unique constraints of simplicity and smallness.
← Software complexity and degrees of freedom
A runtime for structured thought →
I share new posts on my newsletter. If you liked this one, you should consider joining the list.
Have a comment or response? You can email me.