Monocle is a full text search engine indexed on my personal data, like my blog posts and essays, nearly a decade of journal entries, notes, contacts, Tweets, and hopefully more in the future, like emails and web browsing history. It lets me query this entire dataset to look for anything I’ve seen or written about before, and acts as a true “extended memory” for my entire life.

As soon as it went live, Monocle quickly replaced the search field on nearly every other app I use, and became the first and only place I searched for information that I knew I’d seen before. Whether I was searching up someone I had met before, a new blog idea, or a scratch piece of note about how to do something with JavaScript – Monocle had it all, and got it to me in under 5 seconds from anywhere on my computer.
This is the story of how Monocle works, how I built it in a weekend, and how I’ve been using it.
A universal search engine
I first had the idea for Monocle almost exactly a year ago, when I tweeted about potentially building a search engine that only searches my private and personal data.
Thinking about building a "personal search engine"
— Linus (@thesephist) July 13, 2020
A search engine that only indexes my blog, my Tweets, my journal, my calendar/email and contacts, my photos, and browser history.
I want to have better memory without having to remember more stuff. What else should it index?
Since then, I’d thought about executing on this idea a few times, but got distracted or scared away by the potential complexity of the project each time. Then about a week ago, when I was writing about incremental note-taking, I realized that effective recall of information was critical to a good personal knowledge tool. This reignited my interest in this project. This past weekend, I took that idea and built a first prototype with Ink, teaching myself the basics of full text search algorithms in the process.

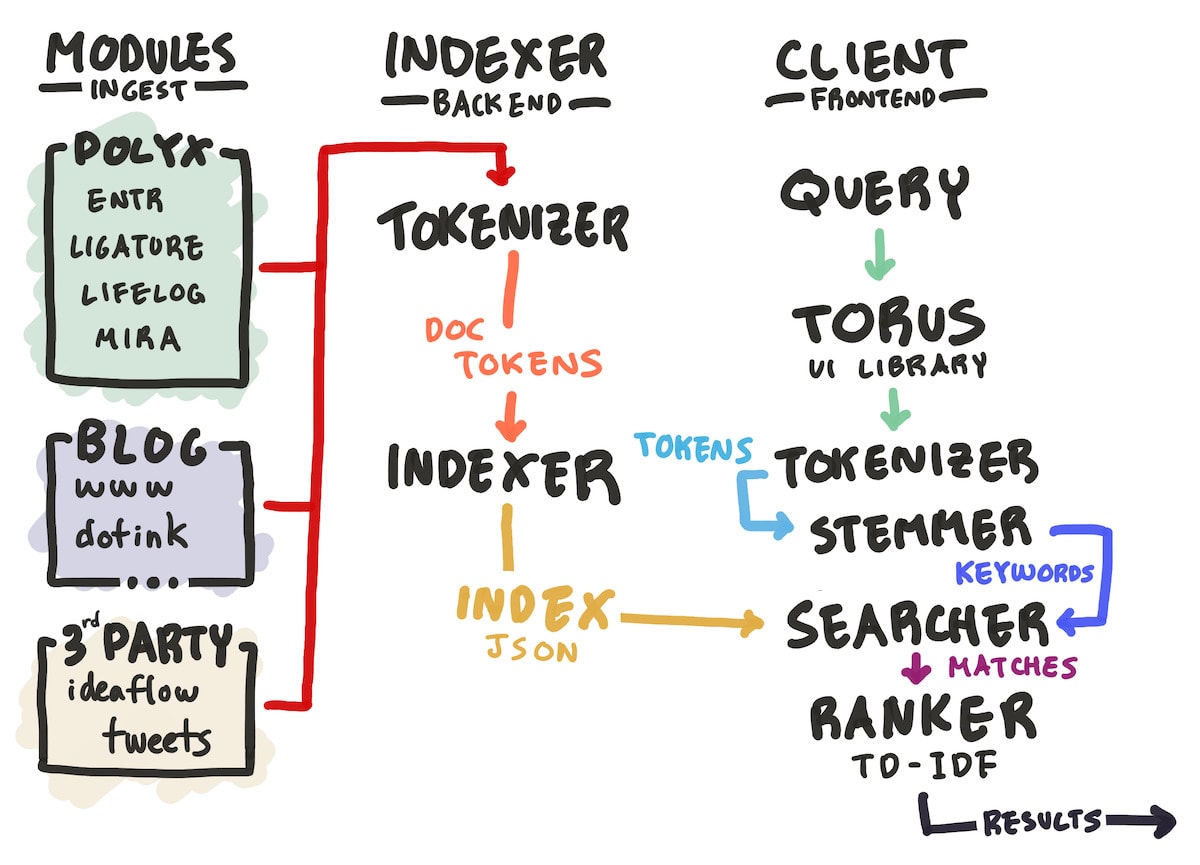
The headline description of Monocle is that it’s a full text search engine indexing only my personal data – I’ve explained the technical details of its architecture in the GitHub repository hosting the code. Here, I want to focus on a few specific design decisions I made in designing Monocle to make it as useful as it could be in my personal workflows.
First, I wanted Monocle’s time-to-first-result to be as quick as possible. By this, I mean that the most important metric of success for a search tool is how quickly I can go from some vague query I have in my mind, to looking through results to find what I need.
One critical constraint this imposed on Monocle’s design was that I needed to be able to search as I typed, with results arriving on every keystroke. Building many small fast tools has taught me that often, making something instantaneous doesn’t just make the tool more efficient – it changes how you use the tool. In this case, I believe searching as-you-type means the search progress becomes less of a slow question-answer cycle, and more of an interactive exploration through my knowledge base of typing a few words to see what information I have, perhaps deleting some characters, and re-typing. To make this experience possible, Monocle loads a compressed, pre-generated index of its document dataset on startup, and performs all search locally in the browser.
Like many of my other tools, the speed constraint also meant I wanted to be able to use the app entirely with the keyboard. The critical-path actions in Monocle – searching, scrolling through a list of results, and previewing them – are all a keystroke away. All of these design decisions together result in a search tool that can almost always help me find what I’m looking for in five seconds from anywhere on my computer.
Second, I wanted an indexer and search algorithm that I owned and understood. This is partly because I just wanted to learn and understand how full-text search engines worked, and the way I learn is often by building tools for myself using that knowledge. Another benefit of a fully custom, from-scratch search algorithm is that if I understand the whole system, I can be aware of its limitations and come back to improve it as I need the algorithm to improve. The “search algorithm” is really a few different parts:
- the indexer, which catalogues keywords in the indexed documents
- the searcher, which reads documents from the index to find matching results
- the stemmer, which expands search queries to include variations of words like “tool” to “tools” or “create” to “creating”
- the ranker, which is responsible for ordering search results by some measure of relevance.
In the future, if I wanted to add extra indexing or querying rules for categorizing results by their source type or date, or have other custom logic related to my data, understanding my own system would give me an edge over using something pre-made. Moreover, using something that’s only as complex as it needs to be for my needs means there are fewer opportunities for the algorithm to break, and more technical flexibility. For example, during development, I had to move the indexer from the client to the server, and my current architecture turned this challenge into little more than a copy-paste of a few lines of code.
I had a lot of fun building a full text search engine and writing custom modules for each of my data sources, but the underlying technology is not cutting-edge by any means – it’s just a full text search algorithm. The magic, as with many of my projects, is what’s possible when you apply such technologies to interesting data in a small, well-known stack that I control.
On privacy and ownership
When I wrote about the value of ownership before, I wrote on personal data ownership:
There’s one other benefit of owning the software services that drive my life. Without a doubt, the most valuable things I have these days is my data. My archive of notes, documents, photographs and music, todo lists, contacts, calendars – these collectively make up my external brain and my identity, which is the last thing I want to lose. I want to own data like this as wholly as I physically can. Storing them through online software services or apps are convenient, but I never know when a third-party notes app is going to run out of funding and shut down, or if a todo list or music app I use is going to pivot and stop caring about me as a user. These days, nearly every piece of data I own is stored and backed up on services and systems that I control from the operating system up.
As I added many of these data sources to Monocle, I realized that many parts of what makes Monocle special are only possible because I own my data and software stack to such a deep extent.
First, Monocle indexes some very personal and private data, like my journal entries. If Monocle was some third-party service from a budding startup, my journal entries would be the last thing I’d want to give up. But because I own and understand the entire search stack, I feel safe letting Monocle index such personal data. As a consequence, the search results I can get back are more personal and significant than anything extant search software could find for me.
Second, because I own my entire data stack, I can have certainty about where much of my data like contacts, notes, and archived journals are stored, and in which format they are saved. This means that writing and maintaining modules to ingest and index these data sources is pretty simple. I don’t have to worry about these data sources going away, or these sources changing their data export format. I simply talk to my file storage system and get back exactly the files I want. I feel that owning my stack for most of the data I needed to index made this problem much more tractable.
An experience report, so far
Monocle has only been live for a few days now – it went live on Saturday for me, and I’m writing this on the following Tuesday. But in that time, I think I’ve searched Monocle at least as many times as I’ve searched Google. In terms of how often I expect to use a tool I built, Monocle ranks in the top five best investments of my time across all my side projects.
In these few days, here are a few things for which I searched Monocle.
- A few specific people whom I had met before, but didn’t remember very well
- Topics I know I had written about before, to find links to blog posts that I could share
- A few companies and projects that I knew I had heard of before, but wasn’t sure from where
- Book recommendations that I had stashed in a few different places in my digital life
- A few Twitter threads that I knew I had shared before about building side projects and communities
When I want to learn something new, I still search the Web. But if I’m trying to remember something from sometime in my past, I now go straight to Monocle, because it’s a more effective and powerful “extended memory” than any note-taking system I have ever used – I don’t need to enter or explicitly save anything; if I ever wrote it down somewhere, it’s here, indexed by Monocle.
In short, Monocle is the closest thing I’ve ever experienced to Vannevar Bush’s Memex. The more I use it, the more I want it to become even more powerful and even more present in my life. And because I own the whole stack, I can do so fearlessly, without any data privacy concerns. In the coming weeks and months, I hope to index other data sources like my browser history, calendar events, and perhaps even my email archive.
While I was building Monocle, I also had a more subtle insight about building my own tools. Monocle isn’t a standalone project by itself, but a cross-cutting infrastructural project that integrates with a wide range of other projects in my portfolio to provide some shared functionality: search. This is my second project like this, after Noct, which provides a shared storage and backup layer for data across many of my apps. After building Noct, backup and file sync was no longer an issue I had to address for each new project. After Monocle, it seems like search also became something that I’ll never have to address again for each individual project. These concerns are addressed universally by infrastructural projects on top of which individual apps can be integrated.
I like this idea of building pieces of dependable, shared infrastructure for cross-cutting concerns across my personal tools. It feels a little bit like building my own personal cloud platform, where I can build small apps that integrate with Monocle and Noct and other pieces of infrastructure and get those extra shared pieces of functionality “for free”. In some ways, building my own programming language and UI framework also give me the same benefit of shared infrastructure. The natural next step in this direction is to build other shared pieces of infrastructure like a universal authentication layer. A “personal cloud” sounds ambitious and grandiose, but it really feels like I’m putting together the right elementary pieces here to run towards that vision.
Writing and thinking about all of these ideas about personal information and recall, I also know that I’m in the vanishingly small minority of people on Earth who have their digital data saved and organized well enough to build a tool like Monocle. For most people, their important information lives across so many different pieces of software across a range of companies and technologies that building a personal Memex would seem impossible. In addition to building something useful for myself, I also want Monocle to serve as a kind of proof-of-concept – a statement piece, perhaps – about what’s possible when we build our own tools and manage our own information. Perhaps with the knowledge of what’s possible, we can push ourselves to draw where we are today closer to where we should be: a universe of small, personal tools that can respect our privacy and agency while leveraging it to help us see the world in new light.
← Note-taking in the wild: living with the Surface Duo
I share new posts on my newsletter. If you liked this one, you should consider joining the list.
Have a comment or response? You can email me.