Of all the projects I’ve made, I receive the most questions about the Ink programming language. Most questions fall into three categories:
- Why did you make a programming language?
- I want to make my own programming language – any advice?
- Why does Ink work the way it does?
This post aims to answer questions (1) and (2) and provide some resources for you to get started on your own language. I think (3) is best left for its own, more technical post.
This post is organized into a few sections.
Why should you?
Making an interpreter for a new programming language is the most technically rewarding project I’ve worked on. It pushed my understanding of fundamental software concepts and helped me comprehend how a computer works at a deeper level.
Programming languages and compilers / interpreters can be black boxes for programmers starting out. They’re tools taken for granted, and you can write good software without necessarily worrying about how the languages and primitive tools you’re using work under the hood. But writing a programming language involves understanding the most meaty parts of the computing stack, from the CPU and memory up through the operating system, in-memory data structures, processes, threads, the stack, all the way up to libraries and applications. It’s the floodgate to the most interesting mathematics in computing – category theory and type systems, algebras, lots of applications of graph theory, complexity analysis, and more. Writing and studying programming languages, I found myself getting more familiar with both the mathematics and the mechanical underpinnings of how computers work.
The project made me a better developer as a result, even if my day-to-day work rarely concerns programming language tooling or compiler writing.
A programming language also has lots of room for expansions, optimizations, and extra creativity even after the project’s version one is “finished”. If you design the initial implementation carefully, you can add new keywords, new features, optimizations, and tools to your language and interpreter / compiler incrementally over time. It’s easy to turn a language into a long-term project and creative outlet, and I’ve enjoyed expanding on my initial implementation while studying other languages after my version-one was complete.
The PL world is broad and deep; pick your battles
Unlike some other areas of software that follow hype cycles, the programming language field has grown and deepened steadily and constantly for a long time in both academia and industry. There’s a lot of literature, research, prior art, and practical advice in the wild about a million different concepts that can be combined into a new language, and a million different variations on how to implement them.
Especially for a personal-project language, I think the most fruitful approach is to pick one or two interesting ideas from the archaeology of computing, and build a programming language that examines and expands on those ideas deeply, rather than try to build the One True Language that’s best at everything and combines the best features of all the languages. Not only is it impossible to make such a language for all use cases, I think that kind of mindset also slows down development, adds unnecessary work, and doesn’t give you the mental space to learn as much about a few interesting topics you might be interested in.
For example, you might be interested in functional programming and immutable data structures. You could try to build a language that’s designed around storing all state in immutable data structures, and study how such data structures can be optimized and manipulated efficiently in a compiler. Or maybe you’re interested in low-level C programming and systems languages, in which case you might try to build a scripting language whose primary goals include elegant interoperability with C APIs and binary interfaces.
Where you start also determines the challenges and tradeoffs you’ll contend with. You might have an easier time writing a Lisp interpreter due to its simpler syntax, because it’s easy to parse compared to, say, a more complex syntax for a language with a static type system. However, Lisps tend to have semantics that are further-removed from the low-level machine code that runs, like closures. So you may trade off the ease of parsing with execution complexity.
Pick your battles carefully, and stick to a few core ideas that you want to study deeply.
Design
Before you write either an interpreter or a compiler, you need to design a language. You can spend time studying category theory and type systems and programming paradigms, but the best thing you can do for yourself at this stage is to study ideas from a wide breadth of programming languages. Don’t just limit yourself to “modern” languages like Rust and Python; reach back into computing history. There’s rich ideas to be reinvented and combined in interesting ways reaching back at least a century into computing and mathematics.
It’s easy to get stuck in the mental model of popular modern OOP-like languages (Python, Ruby, Swift, C++) and spend the most time in this phase designing syntax. But designing the semantics of the language is where you should spend the most of your time, because it’s where the language gets its “feel” and where you’ll learn the most. Semantics are also more difficult to change after the fact than syntax. Some questions to ask yourself, to start thinking about language semantics and ergonomics:
- What types does your language have? Is it checked at compile-time? Does it automatically convert between types as necessary?
- What’s the top-level organizing unit of programs in your language? Languages commonly call this modules, packages, or libraries, but some languages may invent their own concept, like Rust Crates.
- How does the language deal with exceptional conditions, like a missing file, a network access error, or a divide-by-zero error? Do you treat errors like exceptions that bubble up through the call stack, or are errors treated like values, as in C and Go?
- Does your language perform tail recursion optimization? Or do you provide native control-flow tools for looping, like
forandwhileloops? - How much utility do you want to build into the language, as opposed to a standard library? C, for example, doesn’t know about strings – string semantics are provided by the C standard library. Maps and lists are fundamental language constructs in most high-languages, and not so in most low-level ones.
- How does your language think about allocating memory? Is memory automatically allocated as needed? Does the developer need to write code to do so? Is it garbage-collected?
To answer these questions, I think it’s most helpful to just get a taste of a variety of languages in the wild. Here’s a small starter set that I recommend you take a look at, and what ideas I personally found intriguing from each language or language family.
- Lua: a data structure called tables, Lua couroutines, using strings as byte slices, interoperability with C
- Scheme / Clojure: Metaprogramming with macros, homoiconicity, closures, control flow with recursion. Die-hard Common-Lispers may disagree, but Scheme and Clojure are the easiest languages in the Lisp family of languages for me to learn. You should study at least one kind of Lisp.
- Go: structural typing with interfaces, concurrency with blocking green threads
- JavaScript: callback-style concurrency and asynchronous programming, first-class functions, the event loop, Promises
- Awk: Awk is a great example of a small, simple language optimized for one use case: manipulating text files and textual data. It’s very well designed for that workflow, and a inspiration for how effective a small, domain-specific language with simple semantics can be.
- APL / J: APL and J are both array languages, which is a fascinating family of languages well known for its brevity
- Ruby: syntax. Ruby’s well known for its super-flexible syntax, because it lends itself easily to DSLs based on Ruby, like ActiveRecord.
- C: I like C mostly for its simplicity and minimalism, and an uncompromising commitment to compatibility
- Haskell: the type system and parametric polymorphism, variant types, partial application and function type syntax. Once you wrap your mind around it, Haskell is also a good place to start diving deeper into the kinds of elegant programs possible with functional programming.
Implementation
Once you have a design for how a language should work and feel, you should first “test-drive” it to see how programs written in the language feel to use.
Test-drive
In this phase, I usually keep a text document where I experiment with syntax by writing small programs in the new as-yet-nonexistent language. I write notes and questions for myself in comments in the code, and try to implement small algorithms and data structures like recursive mathematical functions, sorting algorithms, and small web servers. I usually hold myself to this stage until most of my questions about syntax and semantics are answered. I also use this phase to test my hypotheses about the core ideas behind the language design. If I designed a language around functional programming and asynchronous, event-driven concurrency, for example, I’d write some sample code in this phase to validate that those ideas combine well together, and lends itself to programs that I’d enjoy writing. If I’m proven wrong, I’ll update my assumptions or play around with the language design to reflect what I’ve learned.
This straw-man design phase is a quick way to make sure that the language you’ve invented in your head could work well for the kinds of programs you want to write, without having to write much implementation.
Build an interpreter/compiler
At their core, interpreters and compilers are layers and layers of small transformations to your source code (a string of text) into some form executable by your computer. The art of designing one boils down to picking good intermediate formats for these transformations to work with, and efficient runtime data structures to encode values and functions of your language within a running program.
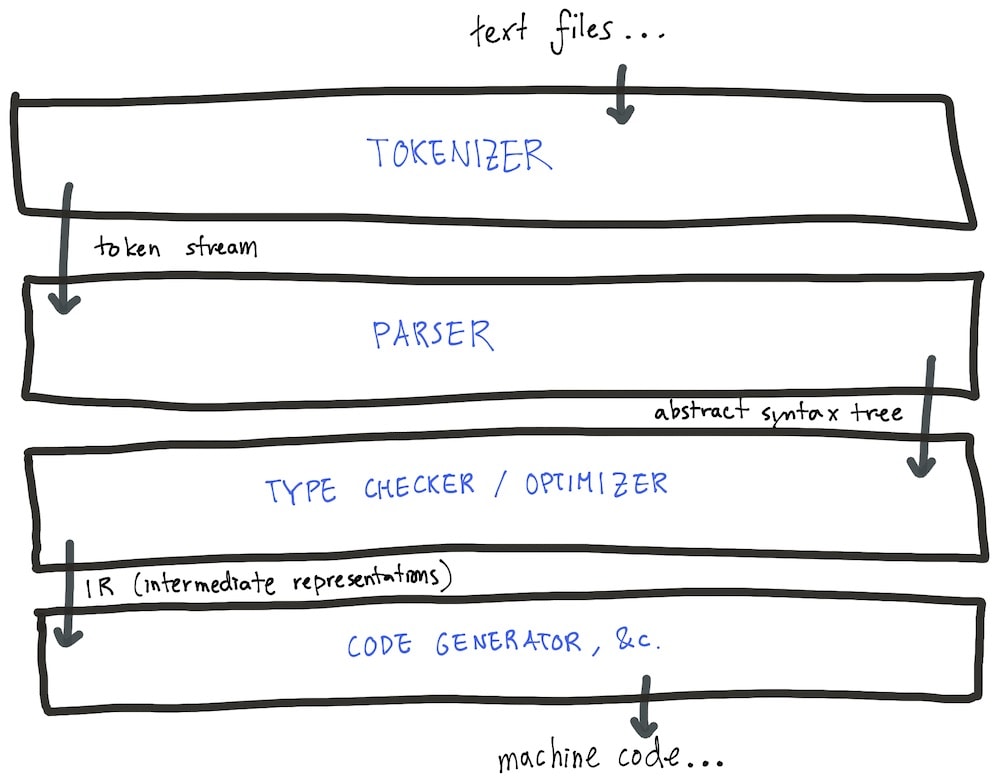
Smart people spend entire careers studying interpreter and compiler design, and I definitely can’t do justice to the topic in a subsection of a blog post. So rather than making an attempt in vain, here, I’ll direct you to the resources I’ve found most useful in my attempt to implement better interpreters and compilers in hobby projects.
Two of my favorite resources on this topic are a pair of ebooks, Crafting Interpreters by Robert Nystrom and Let’s Build A Simple Interpreter by Ruslan Spivak. Both series of articles takes you from a complete beginner in programming languages, to designing and building a simple interpreter step-by-step. Although these books won’t cover every topic in interpretation in detail, it’ll give you a starting point for how each step in the process works, enough to get you to a first working prototype.
While many people have followed through these guides and built versions of their interpreter line-by-line from the book, I skimmed them and used the chapters in the books as references throughout my own journey rather than follow the instructions step-by-step. But nonetheless, these books provide very solid groundwork on top of which you can study additional topics in how interpreters and compilers work.
Though I haven’t read it, I’ve heard praise for the pair of books Writing an Interpreter in Go and Writing a Compiler in Go. They take you through the process of building a programming language and interpreter/compiler from scratch, in the Go programming language. Like the two ebooks introduced above, they cover all the fundamentals and potential pitfalls and considerations you’ll face writing an interpreter or compiler for a realistic language, rather than just building a simple, minimal proof-of-concept.
What follows here is non-essential reading – these articles range from introductory to advanced, and I’ve compiled the list partly for the benefit of my future self. You probably won’t be interested in every single one, and that’s ok.
With that said, Here’s a collection of further reading online on interpreters and compilers …
- Stripe Increment’s “A crash course in compilers” is a great introduction to the topic.
- Peter Norvig’s "(How to Write a (Lisp) Interpreter (in Python))" takes you through writing a very minimal Lisp interpreter in readable Python, and is shorter than any of the books above.
- “Adding a new statement to Go” is a practical guide to hacking on the Go compiler.
- “firefox’s low-latency webassembly compiler” is an interesting deep-dive into tradeoffs made in designing a fast bytecode interpreter.
- The blog for the V8 JavaScript engine, used in Chrome and Node.js, has some of the best explainers of advanced interpreter / JIT compiler tricks I’ve read
- If you feel courageous, I’ve skimmed “Implementing a JIT Compiled Language with Haskell and LLVM” from time to time to learn about how the LLVM compiler backend works.
I’m also a big fan of great technical talks. Here’s a few that I’ve found useful and interesting to watch over the years…
- “Zig: A programming language designed for robustness, optimality, and clarity” by Andrew Kelley
- “The Most Beautiful Program Ever Written” by William Byrd, on Lisp
- “Tulip: A Language for Humans” by Sig Cox and Jeanine Adkisson, on the Tulip programming language and its design, which I think is interesting in many ways
- “The Soul of Erlang and Elixir” by Saša Jurić
- “Implementing a bignum calculator” by Rob Pike, one of the original Go authors. He implements a simple parser + evaluator for a calculator, and shares his approach to designing it.
Lastly, I learned a lot during my work on interpreters by reading the implementations of well-designed and well-documented interpreters and compilers. Of those, I enjoyed:
- Ale, a simple Lisp written in Go
- Lua, written in C. I’ve written a full separate article on interesting design choices in the Lua interpreter, because I’m a big fan of its architecture.
- Wasm3, an interpreter for WebAssembly. I specifically enjoyed the thoughtful and unique bytecode interpreter design, outlined in a design document in the repo.
- Boa, a JavaScript and WebAssembly runtime written in Rust
The list here is just the tip of the iceberg of the blog articles, case studies, and GitHub Issues threads I pored through to add meat to the skeleton I had in my mind of how interpreters and compilers worked. Programming languages is a deep and broad topic! Don’t just settle for knowing the bare basics; really explore what grabs your interest and dive deep, even if the topic seems formidable at first.
Other considerations
As I mentioned above, even after an initial implementation, a toy programming language gives you all the flexibility and creative headroom in the world to implement more advanced features, concepts, and optimizations in your project for you to tinker away. Here’s a small collection of ideas you might explore as extensions of your project, if you’re so inclined.
More sophisticated type systems. Studying type systems piqued my interest in two related topics, category theory and implementations of elegant data structures with advanced type systems in languages like Haskell and Elm. If you’re coming from Java, JavaScript, or Python, studying how types work in Swift, TypeScript, or Rust may be a good starting point.
Optimizations. How can you make your interpreter or compiler faster? And what does it even mean for it to be faster? Faster at parsing and compiling the code? Produce faster code in the end? There’s no end to prior art and literature in the wild on the topic of compiler performance.
Add a C foreign function interface (FFI). An FFI is a layer of interoperability between your language and another, usually C binaries. Adding a C FFI might be a good place for you to learn about the low-level details of how programs are compiled into executable files, and about executable file formats and code generation.
JIT compilation. Some of the most common and fastest language runtimes, like Chrome’s V8 and LuaJIT for Lua, are actually neither completely vanilla interpreters nor full compilers, but hybrid, just-in-time (JIT) compilers that generate compiled machine code on the fly. JITs are sometimes able to make better tradeoffs between performance and runtime dynamism in the programming language than simple interpreters or compilers, at the cost of more complexity in the compiler.
Start small, get creative, ask questions
I’ve covered a lot of ground here, but this isn’t where I started, and you certainly don’t need to digest all of the material I shared here before you start hacking on your own language. Start small. Be ambitious and be creative, but be smart and work incrementally.
You don’t have to understand everything before you start writing your language. Much of what I learned in my own process was a consequence of my diving into completely new and foreign topics until I understood bigger and bigger fractions of what I’d read online about it.
Programming languages is one of my favorite fields of computing for its diversity and depth. Just be creative, and ask good questions – I hope you find the possibilities of building your very own tools for programming as magical as I.
I share new posts on my newsletter. If you liked this one, you should consider joining the list.
Have a comment or response? You can email me.